
完全分布式高可用集群(Flink)
Flink
零、前提条件
Flink集群规划
| hadoop1 | hadoop2 | hadoop3 |
|---|---|---|
| JobManager | TaskManager | TaskManager |
- 上传安装包(在hadoop1操作)
- 解压安装包
1 | tar -zxvf /software/flink-1.19.1-bin-scala_2.12.tgz -C /opt |
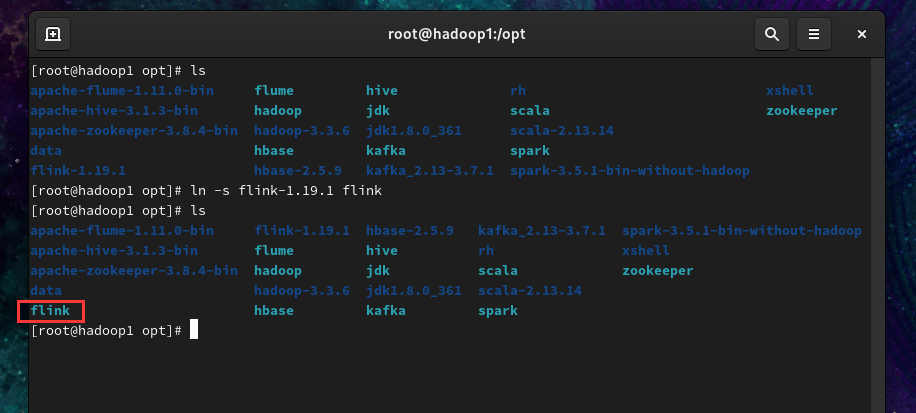
- 配置环境变量,添加如下内容
1 | export FLINK_HOME=/opt/flink |
让环境变量生效
1 | source /etc/profile |
验证版本号
1 | flink -v |
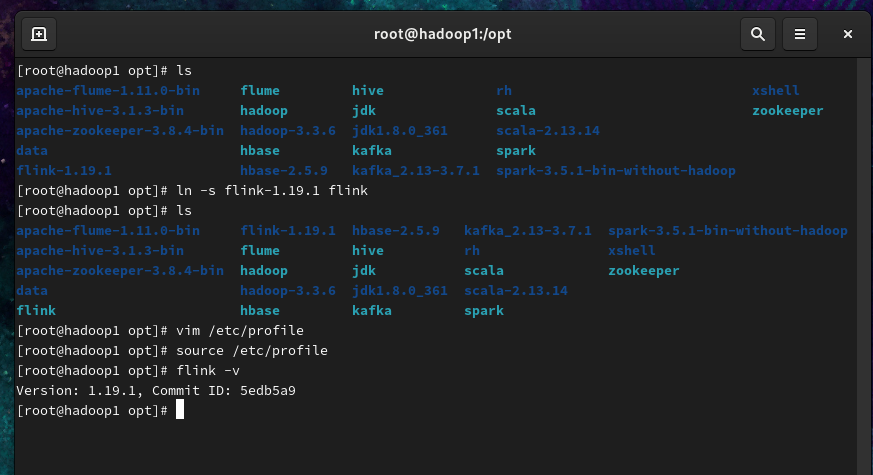
看到如上版本号字样,说明环境变量配置成功。
一、配置Flink
进入flink配置目录/opt/flink/conf,查看配置文件
- 配置
flink-conf.yaml
1 | vim flink-conf.yaml |
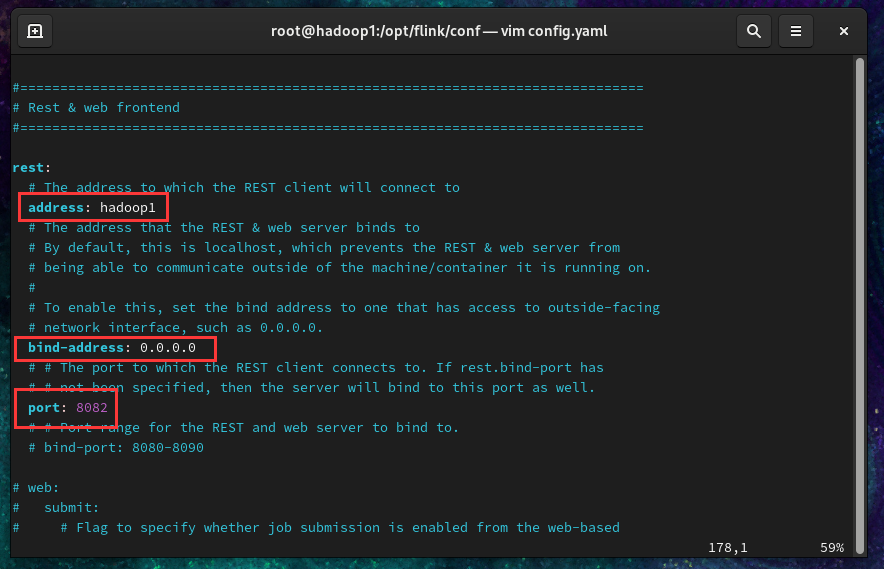
找到相关配置项并修改,如下
1 | jobmanager.rpc.address: hadoop1 |
(下图以rest为例)
- 配置workers
1 | vim workers |
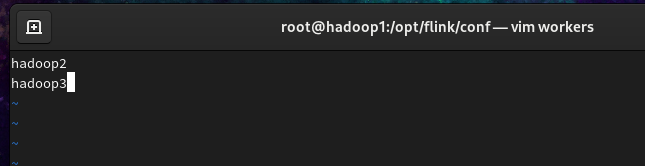
把原有内容删除,添加内容如下:
1 | hadoop2 |
- 配置masters
1 | vim masters |
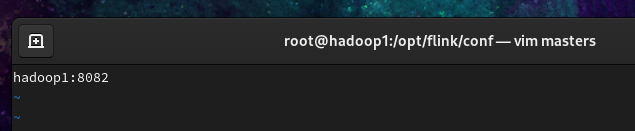
修改后内容如下:(由于8081端口被Spark占用了,改成8082)
1 | hadoop1:8082 |
- 分发flink安装目录
确保hadoop2、hadoop3机器已开启的情况下,执行如下分发命令(注意分发的是flink-1.19.1,不是flink)。
1 | scp -r /opt/flink-1.19.1 root@hadoop2:/opt/ |
让环境变量生效
1 | ssh hadoop2 "source /etc/profile" |
- 修改hadoop2和hadoop3的配置
进入hadoop2机器flink的配置目录/opt/flink-1.19.1/conf,配置config.yaml文件
将taskmanager.host的值修改为hadoop2
1 | taskmanager.host: hadoop2 |
hadoop3机器同理修改为hadoop3
- 启动flink集群
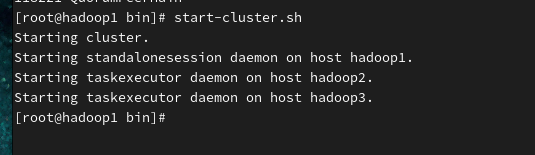
1)在hadoop1机器,执行如下命令启动集群
1 | start-cluster.sh |
2)查看进程
1 | sh /opt/xshell/xjps.sh |
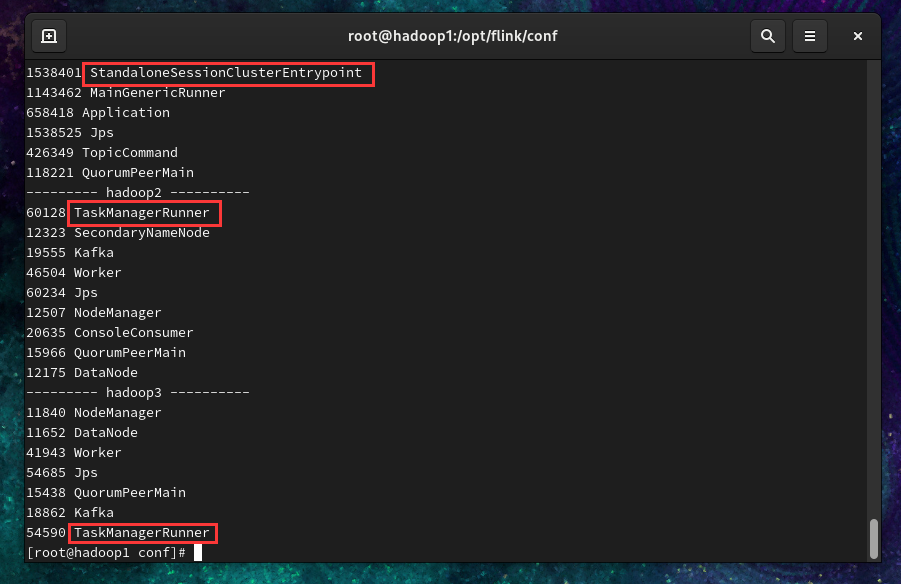
hadoop1有StandaloneSessionClusterEntrypoint进程
hadoop2有TaskManagerRunner进程
hadoop3有TaskManagerRunner进程
看到如上进程,说明flink集群配置成功。
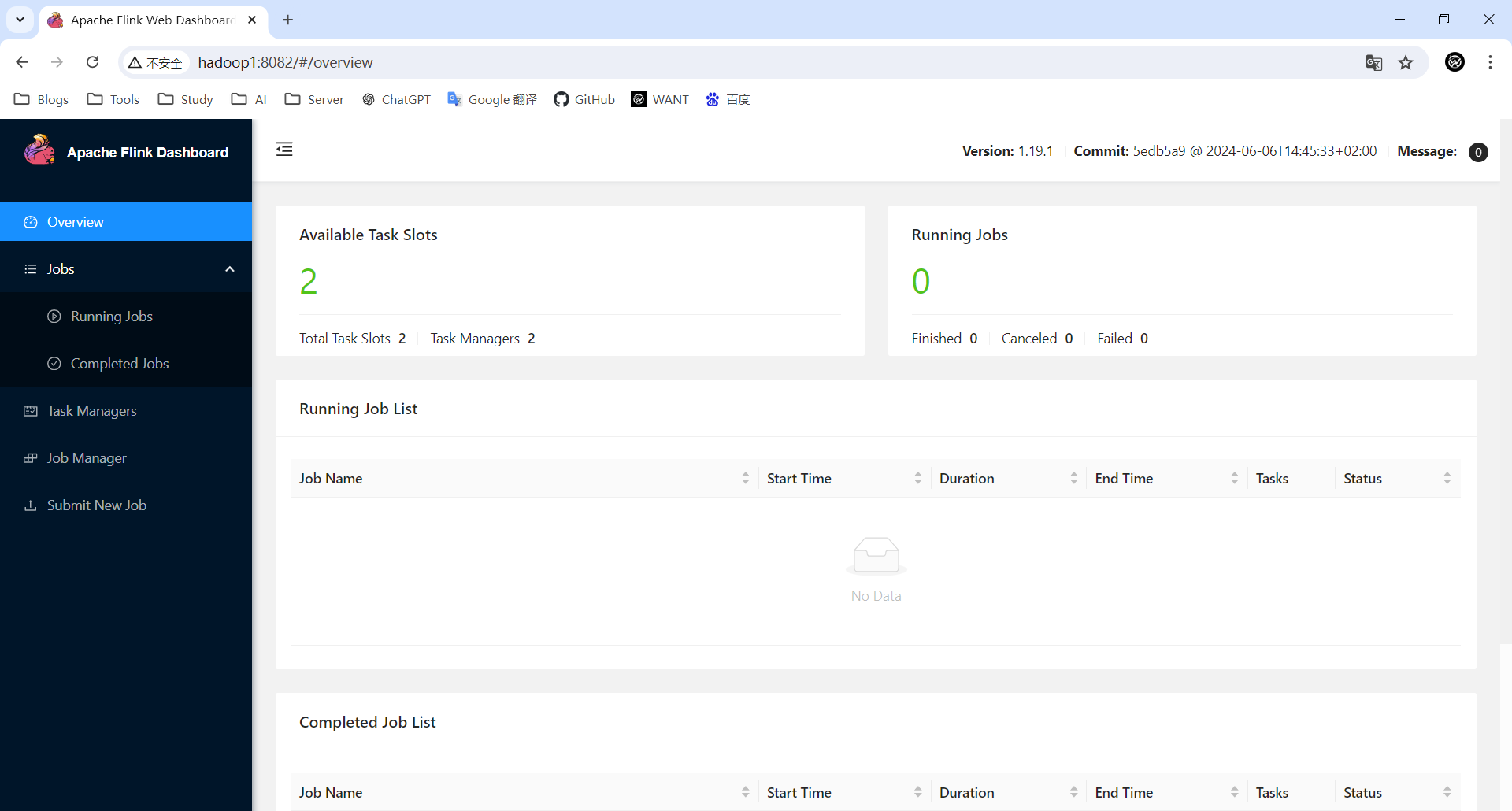
网页查看(http://hadoop1:8082)
3)关闭flink集群
1 | stop-cluster.sh |
二、测试Flink
- 运行flink提供的WordCount案例程序
1 | flink run /opt/flink/examples/streaming/WordCount.jar |
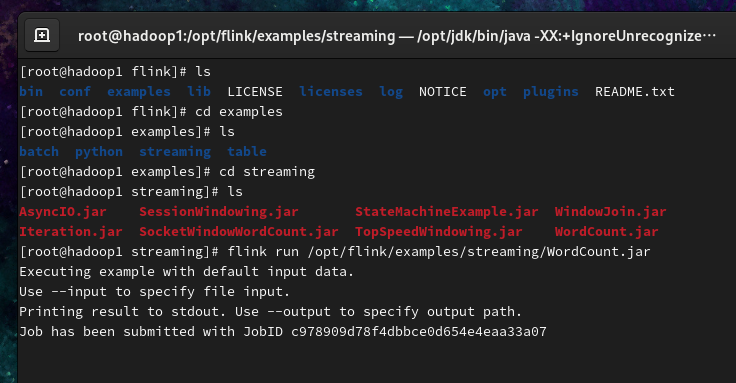
查看输出的WordCount结果的末尾10行数据
(运行时需要超过100G的内存,本人的内存不足,无法运行出结果)
Web UI查看运行结果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Want595!
 微信
微信
评论
