Flume
零、资源准备
- apache-flume-1.11.0-bin.tar.gz
一、搭建完全分布式集群(Flume)
注意,本文只需要在hadoop1机器进行操作。
- Flume安装
1.1 上传压缩包
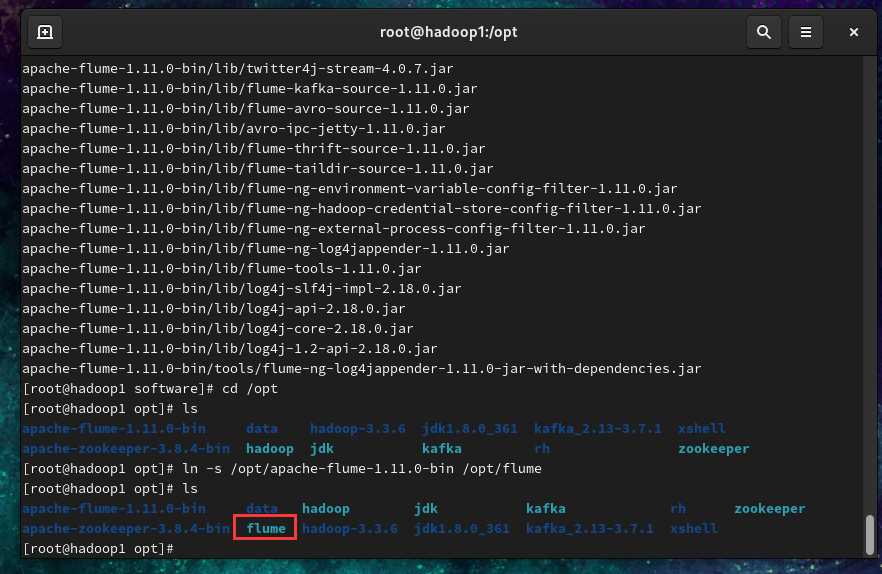
1.2 解压到安装目录下并设置软链接(或重命名)
1
2
| tar -zxvf /software/apache-flume-1.11.0-bin.tar.gz -C /opt/
ln -s /opt/apache-flume-1.11.0-bin /opt/flume
|
- Flume配置(以hadoop1为例)
2.1 复制一个/opt/flume/conf/flume-env.sh文件
1
2
| cp /opt/flume/conf/flume-env.sh.template /opt/flume/conf/flume-env.sh
vim /opt/flume/conf/flume-env.sh
|
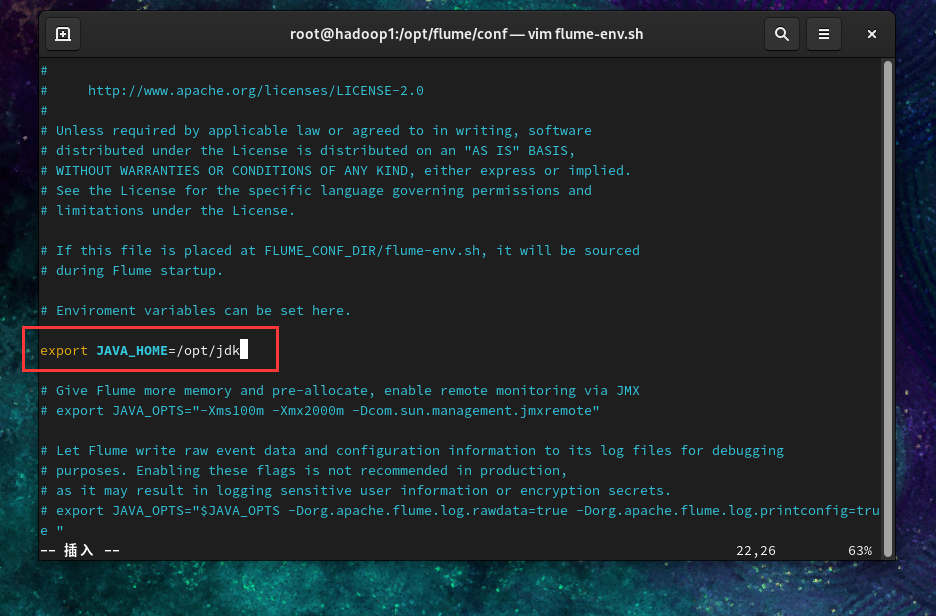
2.2 修改/opt/flume/conf/flume-env.sh文件
1
| export JAVA_HOME=/opt/jdk
|
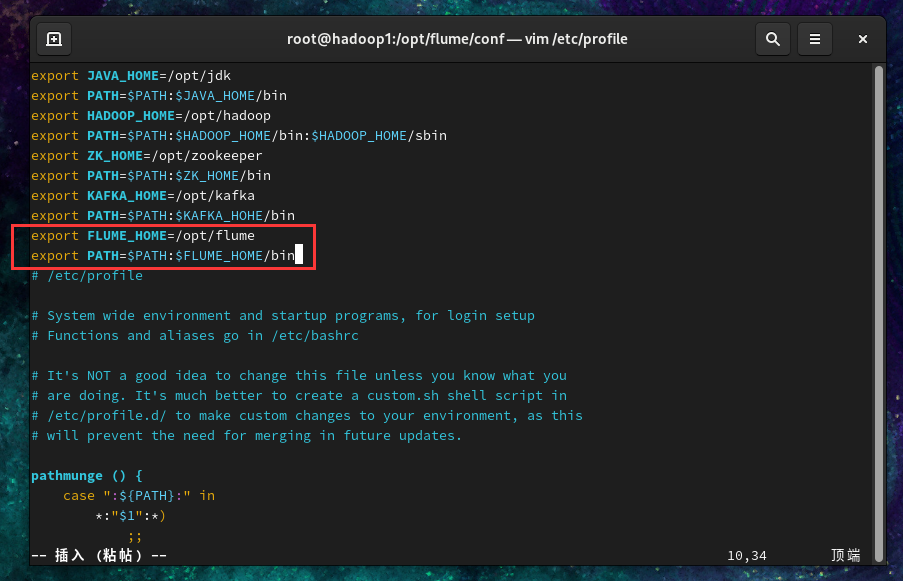
2.3 配置环境变量/etc/profile,增加以下内容(记得source)
1
2
| export FLUME_HOME=/opt/flume
export PATH=$PATH:$FLUME_HOME/bin
|
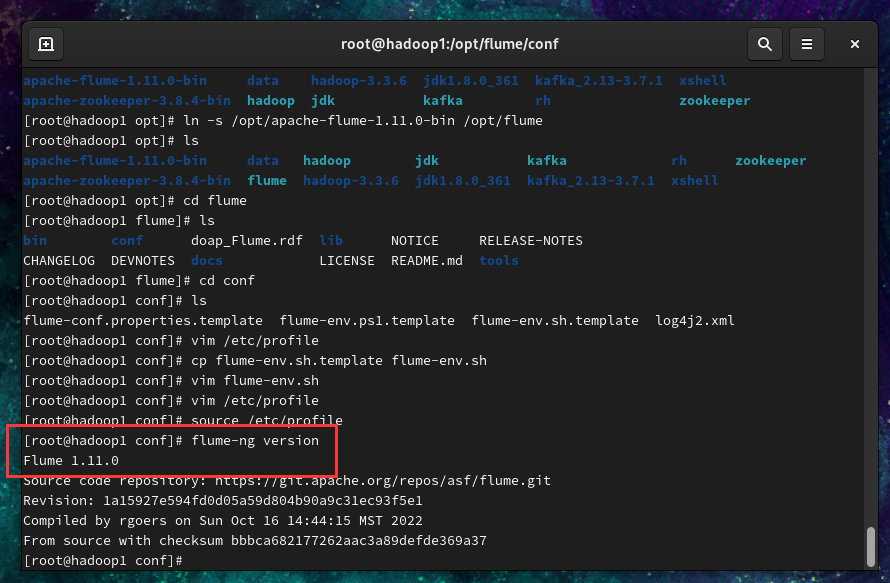
2.4 检查是否安装成功
输入命令flume-ng version
二、测试Flume集群
Flume 除了可以监控单个日志文件外,还能监控整个目录,比如我们希望监控某个目录中出现的新文件。
- 在
/opt/data/目录下创建一个files文件夹。
1
2
| cd /opt/data
mkdir files
|
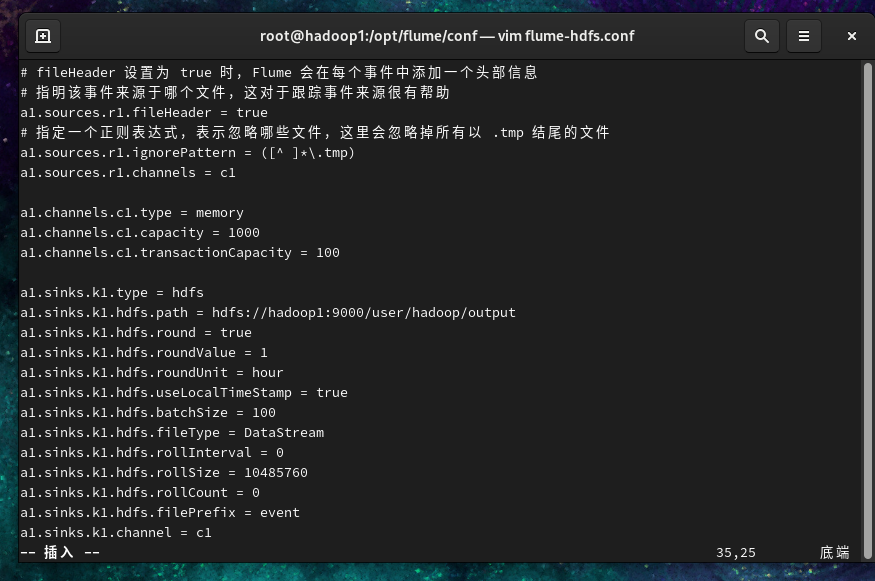
- 在
/opt/flume/conf/目录下创建一个配置文件 flume-hdfs.conf,填入以下内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 指定 Source 的类型是 spooldir
a1.sources.r1.type = spooldir
# 指定监控的目录,会处理已存在和新增的文件
a1.sources.r1.spoolDir = /opt/data/files
# Flume 会读取文件的内容,转成独立的 Flume 事件,然后发送到 Channel
# 一旦文件读取完成,Flume 会自动给文件增加一个 .COMPLETED 后缀,以防止重复读取
a1.sources.r1.fileSuffix = .COMPLETED
# fileHeader 设置为 true 时,Flume 会在每个事件中添加一个头部信息
# 指明该事件来源于哪个文件,这对于跟踪事件来源很有帮助
a1.sources.r1.fileHeader = true
# 指定一个正则表达式,表示忽略哪些文件,这里会忽略掉所有以 .tmp 结尾的文件
a1.sources.r1.ignorePattern = ([^ ]*\.tmp)
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop1:9000/user/hadoop/output
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 10485760
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = event
a1.sinks.k1.channel = c1
|
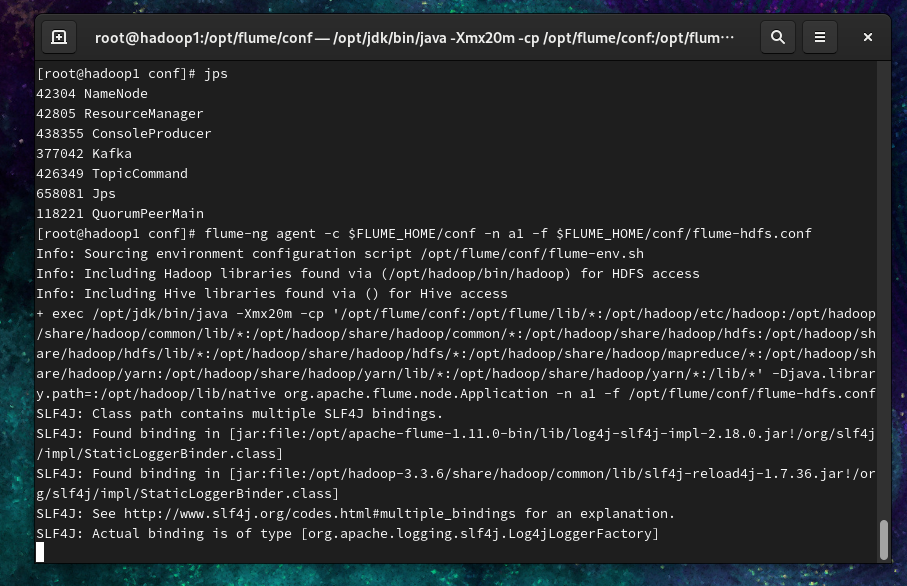
- 启动Flume(确保已启动Hadoop)
1
| flume-ng agent -c $FLUME_HOME/conf -n a1 -f $FLUME_HOME/conf/flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console
|
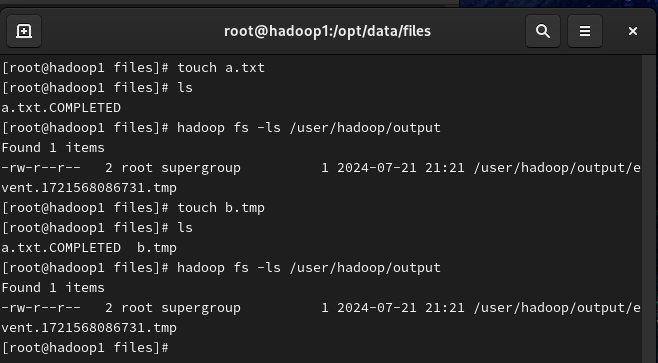
- 然后我们往 files 目录中创建几个新文件。
Flume 会每隔 500 毫秒扫描一次监控目录的文件变动,然后检测到 files 目录中新增了 a.txt 并进行读取。一旦读取完毕,会自动给文件增加一个 .COMPLETED 后缀,表示读取完毕。而 b.tmp 则没有读取,因为过滤掉了以 .tmp 结尾的文件。 注意:监控目录和监控单个文件有所不同,如果是监控单个文件,那么可以不停地追加内容。但如果是监控目录,那么应该向目录中上传已经包含完整内容的文件,而不要在监控的目录中对文件进行修改。
- 查看HDFS(http://192.168.121.160:9870/explorer.html#/user/hadoop/output)的内容,显然文件已成功上传。


 微信
微信