import pandas as pd import numpy as np import jieba import re import logging import fasttext from multiprocessing import cpu_count import matplotlib.pyplot as plt from sklearn.cluster import KMeans import pickle import os from wordcloud import WordCloud
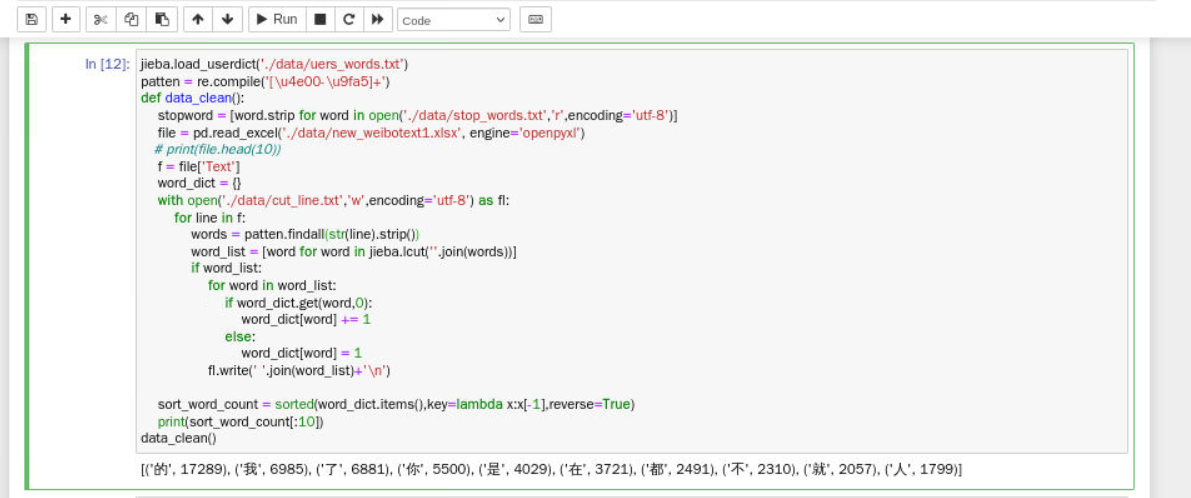
def data_clean(): stopword = [word.strip for word in open('./data/stop_words.txt','r',encoding='utf-8')] file = pd.read_excel('./data/new_weibotext1.xlsx', engine='openpyxl') # print(file.head(10)) f = file['Text'] word_dict = {} with open('./data/cut_line.txt','w',encoding='utf-8') as fl: for line in f: words = patten.findall(str(line).strip()) word_list = [word for word in jieba.lcut(''.join(words))] if word_list: for word in word_list: if word_dict.get(word,0): word_dict[word] += 1 else: word_dict[word] = 1 fl.write(' '.join(word_list)+'\n')
6.11 在第四个Cell中,定义Word2Vec类,在类里面定义train_w2v方法,方法里面使用fasttext.train_unsupervised函数,为了学习词向量(向量表示),并且在学习开始时输出’Start training word vectors……’,保存好模型后print输出’Word vector train done!!!’。代码清单如下所示。
1 2 3 4 5 6 7 8
class Word2Vec: def train_w2v(self,file): print('Start training word vectors......') w2vModel = fasttext.train_unsupervised(file, model='skipgram', epoch=100, lr=0.01, dim=100, ws=5, word_ngrams=2, bucket=2000000) w2vModel.save_model('./model/word2vec_model_100.bin') print('Word vector train done!!!')
def file_embedding(self,file,model): out_vector = [] for line in file: #print(line) if line.strip(): vector = self.sentences_embedding(line.strip(),model) out_vector.append(vector) else: pass return out_vector
class MODEL: def __init__(self,path,model_path): self.file = self.read_file(path) # print(list(self.file)) if not os.path.exists('./model/word2vec_model_100.bin'): w2v.train_w2v(path) self.w2v_model = w2v.load_model(model_path)
6.21 以只读方式打开文件并去除文档中的空格。代码如下所示。
1 2 3 4 5
def read_file(self,path): file = open(path,'r',encoding='utf-8') return [line.strip() for line in file if line.strip()] def all_line(self): return [line.strip() for line in self.file if line.strip()]
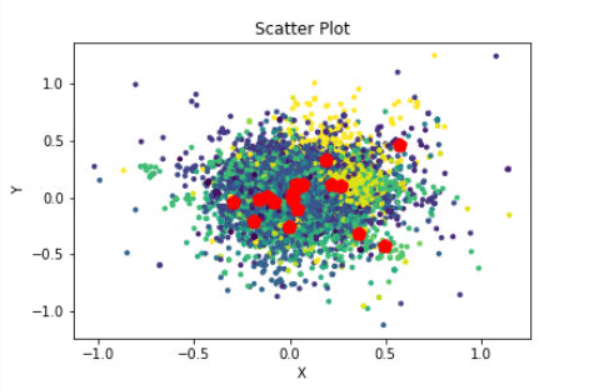
def center_sim(self): ''' 统计几个聚类中心的之间的距离,返回频次最高的topk个中心 :return: 返回频次最高的topk个中心 ''' i= 0 sim_dict = {} for vec1 in self.centers: i += 1 if i <= len(self.centers): j = i for vec2 in self.centers[i:]: cos = sim.vectorCosine(vec1,vec2) # print(cos) sim_dict[cos] = (i-1,j) j += 1 sort_sim = sorted(sim_dict.items(),key=lambda x:x[0],reverse=True) #print(sort_sim[:10]) num_dict = {} for item in sort_sim[:10]: center_nums = item[-1] for i in center_nums: # print(i) if i in num_dict.keys(): num_dict[i] += 1 else: num_dict[i] = 1 top_center = sorted(num_dict.items(),key=lambda x:x[-1],reverse=True)[:2] #print('top_center:{}'.format(top_center)) return [num[0] for num in top_center]

 微信
微信