
大数据行业应用-情感分析
大数据行业应用-情感分析
1、数据准备
1.1在master节点打开一个终端,进入虚拟环境zkbc
1 | [zkpk@master ~]$ source activate zkbc |
1.2在zkpk家目录下创建实验文件夹sparkmllib,并进入实验文件夹sparkmllib
1 | (zkbc)[zkpk@master ~]$ mkdir sparkmllib |
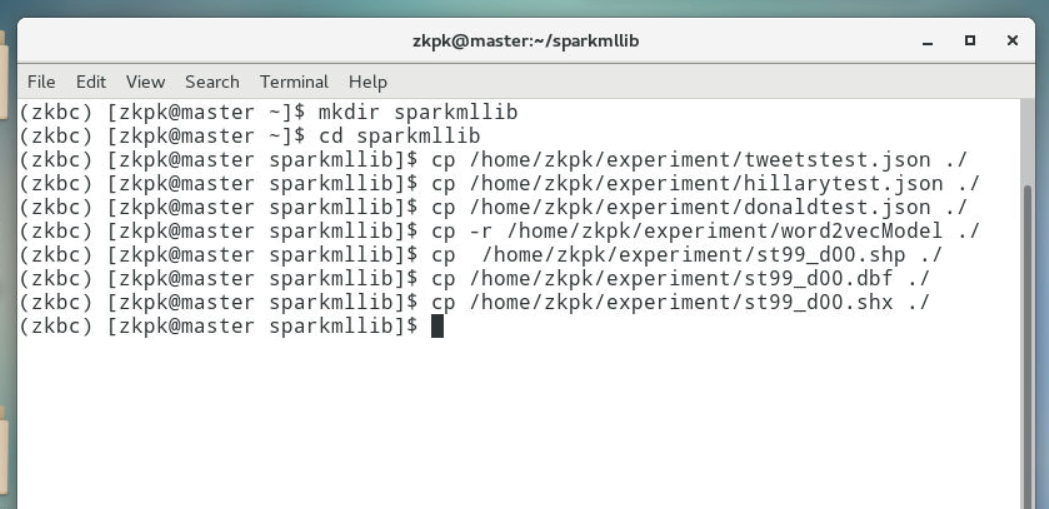
1.3拷贝训练集和测试集数据到实验文件夹中
1 | (zkbc)[zkpk@master sparkmllib]$ cp /home/zkpk/experiment/tweetstest.json ./ |
1.4拷贝文件向量化模型文件夹word2vecModel到实验文件夹中
1 | (zkbc)[zkpk@master sparkmllib]$ cp -r /home/zkpk/experiment/word2vecModel ./ |
1.5拷贝basemap绘制美国地图所需的shapefile到实验文件夹中
1 | (zkbc)[zkpk@master sparkmllib]$ cp /home/zkpk/experiment/st99_d00.shp ./ |
2、推特文本转换成向量
2.1利用vim编辑器创建python文件sparktest.py
1 | (zkbc)[zkpk@master sparkmllib]$ vim sparktest.py |
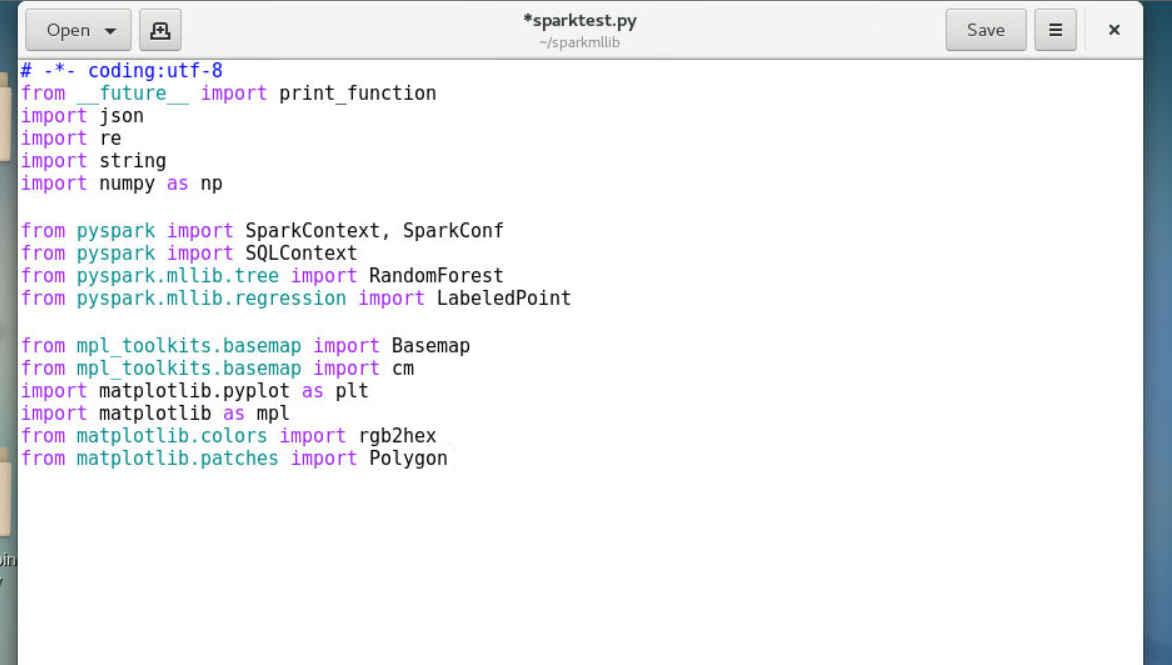
2.2在sparktest.py中键入代码
2.2.1定义编码格式utf8
2.2.2导入python基本库、Spark依赖库、basemap可视化库等
1 | # -*- coding:utf-8 |
2.2.3Spark MLlib中提供的机器学习模型处理的是向量形式的数据,因此我们需将文本转换为向量形式,为了节省时间,这里我们利用Spark提供的Word2Vec功能结合其提供的text8文件中的一部分单词进行了word2vec模型的预训练,并将模型保存至word2vecModel/data文件夹中,因此本次实验中将推特数据转换为向量时直接调用此模型即可
2.2.4定义分词文本转换为向量的函数
1 | def doc2vec(document): |
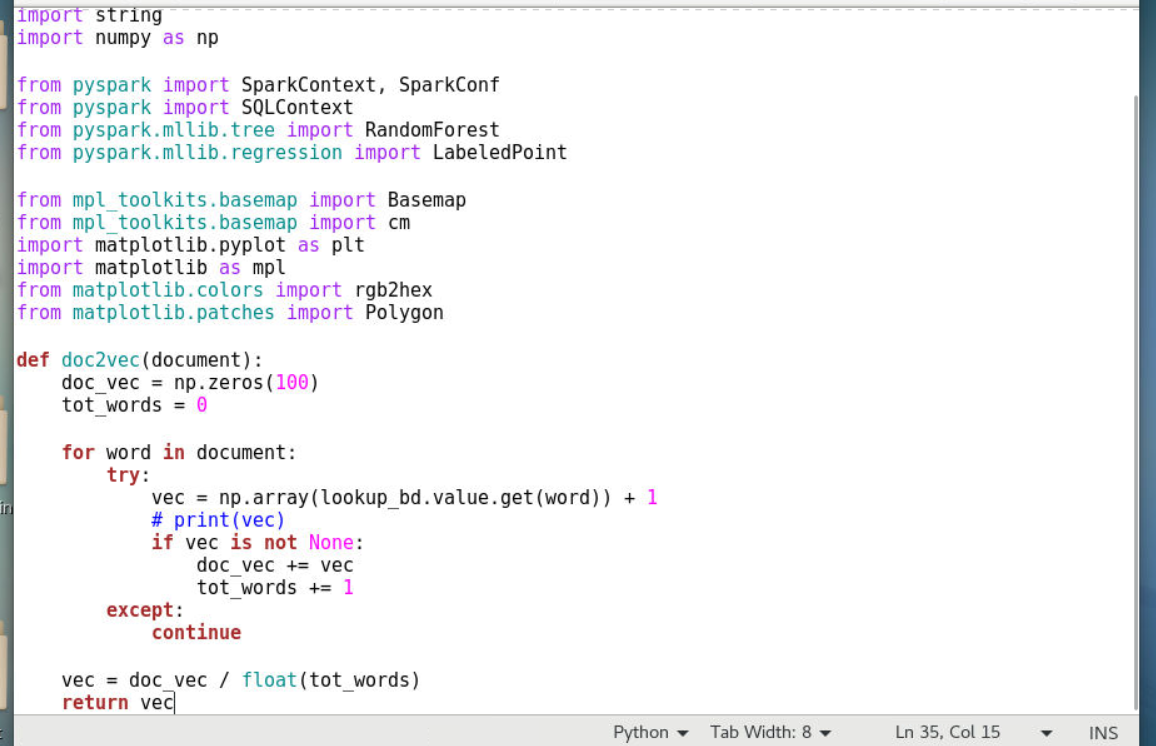
2.2.4.1本函数接受一个分词后的文本参数
2.2.4.2先定义一个100维的向量doc_vec
2.2.4.3遍历查找文本中的词在预训练模型word2vec中是否存在
2.2.4.4如果该特征词在预先训练好的模型中,则添加到向量中,否则继续下一循环
2.2.4.5最后获得词向量/匹配词总数
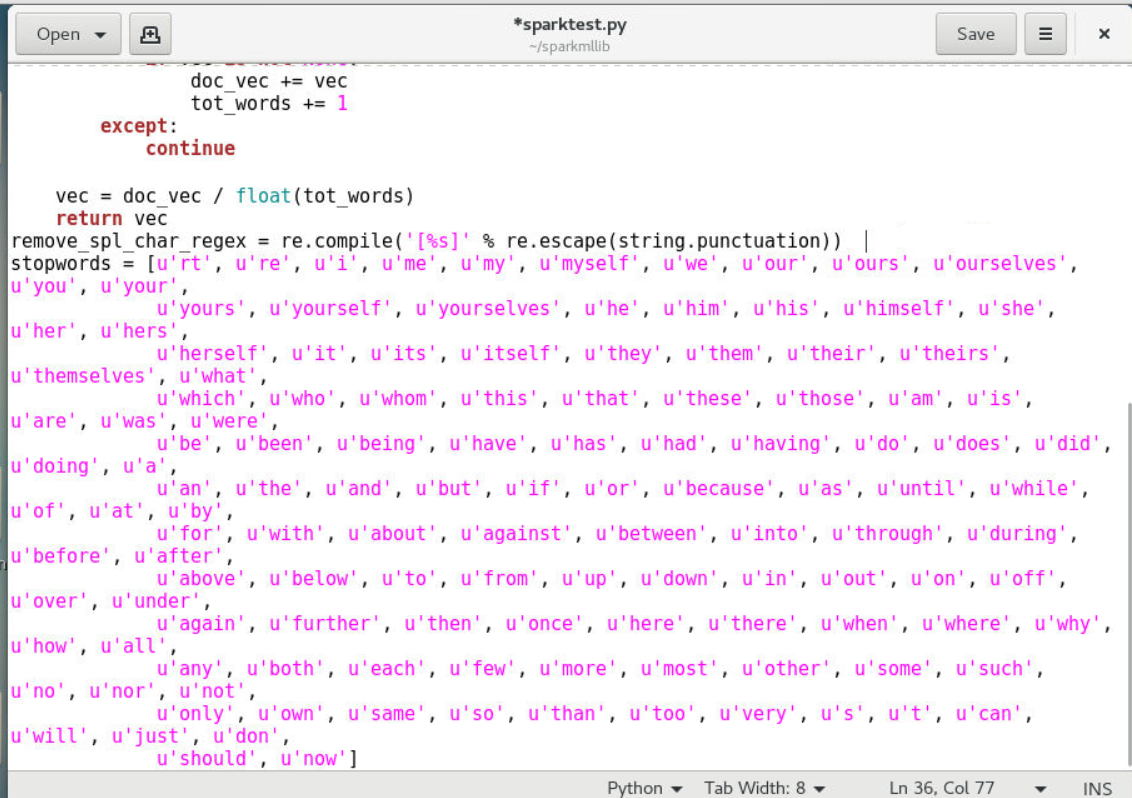
2.2.5定义推特文本中的停用词、标点符号、url等
2.2.5.1定义Python正则re模块去除特殊字符,如匹配特殊字符%S
2.2.5.2定义使用re模块的 escape函数去除字符串中的标点符号
2.2.5.3定义停用词组stopwords
1 | remove_spl_char_regex = re.compile('[%s]' % re.escape(string.punctuation)) # 正则去除特殊字符 |
3、数据分词
3.1定义Segmentation函数对推特文本进行分词
1 | def Segmentation(text): |
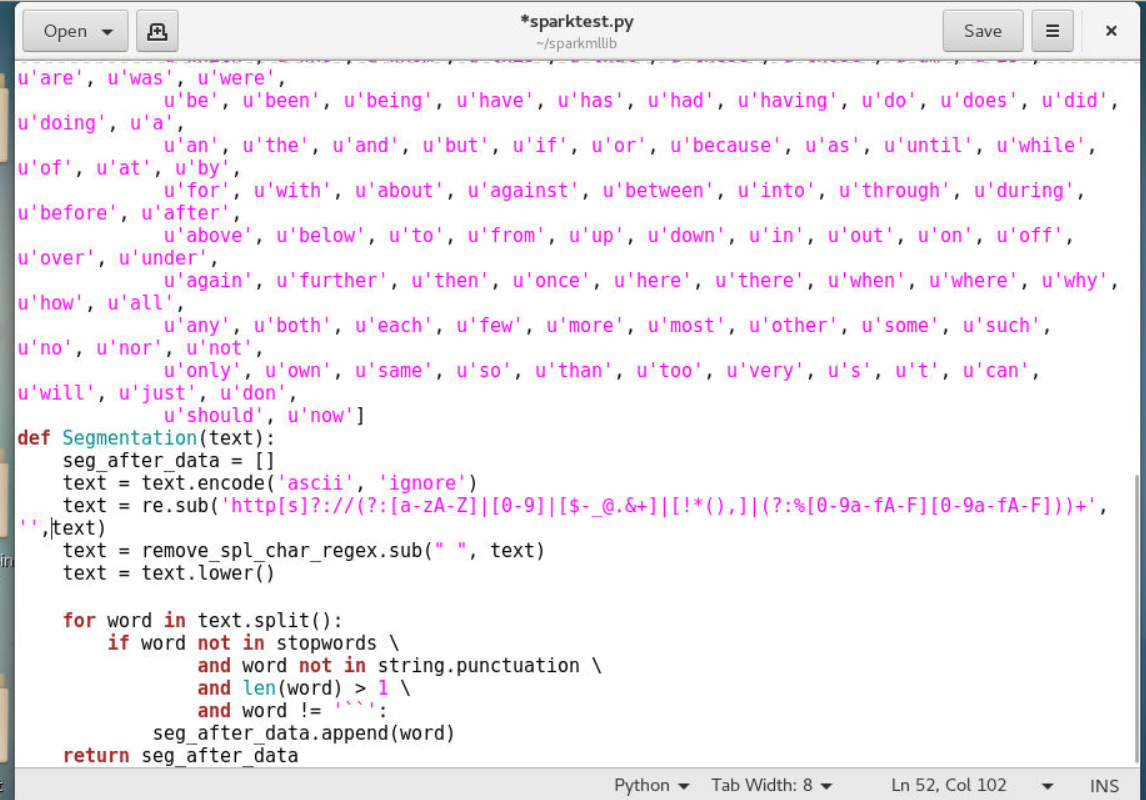
3.1.1本函数接受原始数据文本,针对文本数据进行分词处理
3.1.2推特分词为英文分词,只需将每个单词分开即可(与中文分词不同)
3.1.3使用Python正则re模块将url替换为空格
3.1.4调用去除特殊字符方法remove_spl_char_regex去除文件中的特殊字符
3.1.5判断文本中的词是否不是停用词组中的词,且是否不包含标点符号,且是否词的长度大于1,且是否该词不等于空字符串,如果以上都是则则追加到seg_after_data中不做任何操作,如果有一条不满足则不做任何操作,继续下个词的判断
4、构建basemap可视化图表
4.1定义可视化函数res_visulization
4.1.1参数perd_result为sparkmllib情感分析的结果
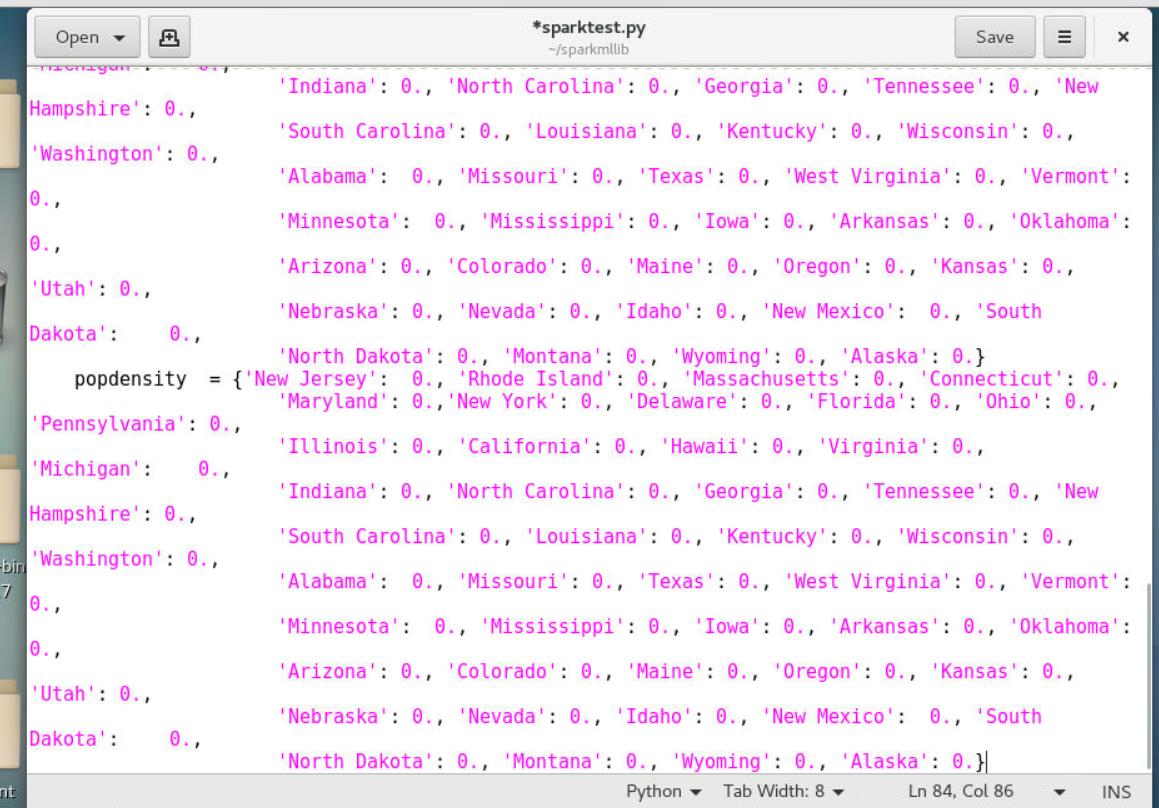
4.1.2创建两个python字典
4.1.3popdensity_ori字典用于保存原始数据的不同州的情感属性
4.1.4popdensity字典用于保存随机森林分析的不同州的情感属性
1 | def res_visulization(pred_result): |
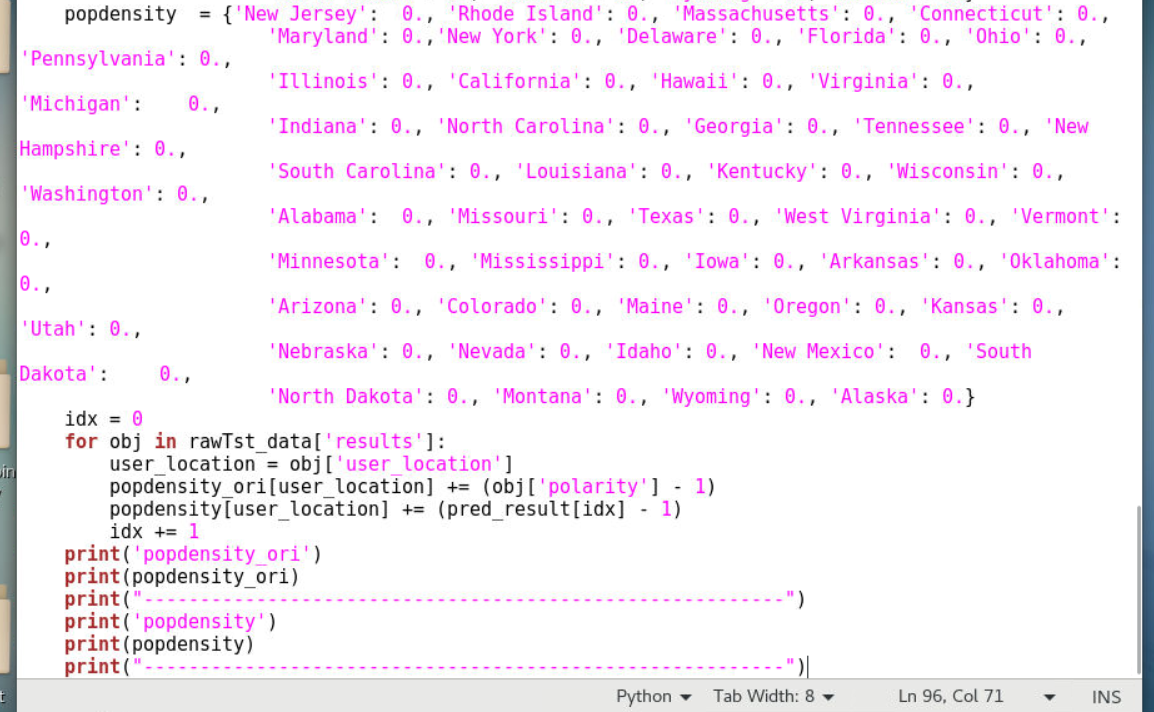
4.1.5获取rawTst_data中的result字段中的积极性polarity并根据user_location字段保存在popdensity_ori中(rawTst_data为测试集hillarytest.json,后面的代码中会定义),获取随机森林预测的结果的积极性并根据user_location字段保存在popdensity中(pred_result是本函数参数)
4.1.6在终端打印输出字段数据
1 | idx = 0 |
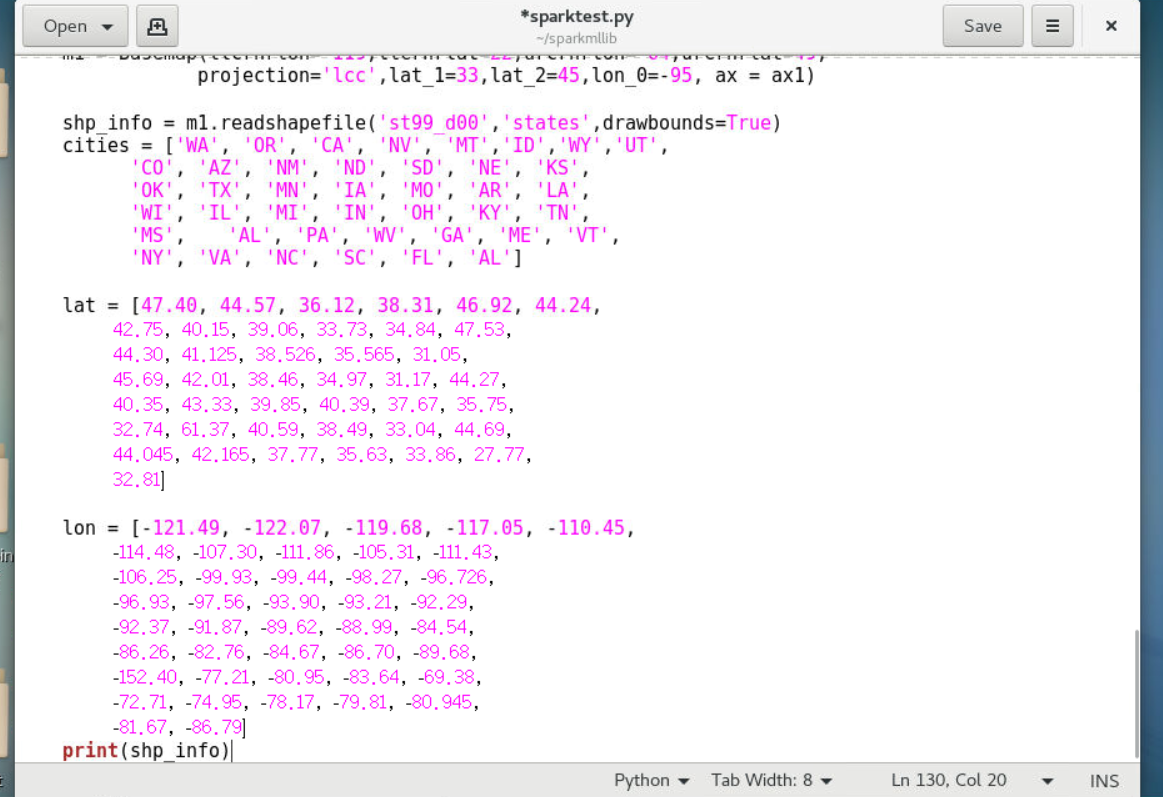
4.1.7在可视化结果中利用basemap中matplotlib的pyplot生成画布figure并定义尺寸,为画布创建两个图实例ax1和ax3,并设置坐标属性(add_axes中的参数分别代表left:绘图区左侧边缘线与Figure画布左侧边缘线的距离;bottom:绘图区底部边线与Figure画布底部边缘线的距离;width:绘图区的宽度;height:绘图区的高度)。创建图m1应用图实例ax1,用于展示原始数据情感分析的结果,读取配置文件st99_d00来获取美国兰伯特正形图下的48个州并画出州边界,定义各个州的缩写以及各个州的经度和纬度,这里我们只给出了部分州的缩写,美国较小的城市没有具体列出,示例代码如下:
1 | # 获取美国兰伯特正形图下的48个州 |
4.1.8定义颜色集color和color2,分别用于保存原始数据的情感分析颜色和spark mllib分析预测的情感分析颜色,使用cm.GMT_polar渐变色用以展示不同的情感;分别获取基于测试数据和基于模型分析的48个大州情感属性的最大和最小值
1 | 根据人口密度选择每个州的颜色 |
4.1.9循环获取美国48个州的名字(跳过哥伦毕亚特区DC和波多黎各自治邦),并赋值给statname变量,根据州名获取不同情感属性集中的情感等级,判断并确定颜色,不同州的颜色随情感越积极越红,越消极越蓝,无感状态时为无色,蓝色为小于cmap的0.5,无色为cmap的0.5,红色为大于cmap的0.5
1 | for shapedict in m1.states_info: |
4.1.10根据州名遍历所有的州,并根据大州名获取当前轴实例ploy,填充颜色
1 | 遍历大州名称,为每一个州绘制颜色 |
4.1.11为图m1绘制经纬线lon、lat,并在地图上添加不同州的的缩写,设置图形标题,定义图m2应用图实例ax3,根据大州名为每一个州确定颜色,并根据大州名获取当前轴实例ploy,为图m2绘制经纬线lon、lat,设置x轴y轴坐标,设置图形标题,用于展示随机森林预测的结果
1 | m1.drawparallels(np.arange(25,65,20),labels=[1,0,0,0]) |
4.2构建颜色对比渐变条目
4.2.1定义图实例ax2,设置坐标属性(add_axes中的参数分别代表left:绘图区左侧边缘线与Figure画布左侧边缘线的距离;bottom:绘图区底部边线与Figure画布底部边缘线的距离;width:绘图区的宽度;height:绘图区的高度),添加渐变色条colorbar,设置图形x轴的三个情感极性,方便对应颜色查看情感属性
1 | ax2 = fig.add_axes([0.05, 0.10, 0.9, 0.05]) |
4.2.2创建sparkContext并设置其名称和日志级别问ERROR(即除正常日志外只显示ERROR日志)
1 | conf = SparkConf().setAppName("zkpk_test") |
4.2.3利用sparkContext创建sqlContext,再利用sqlContext读入预先训练好的文本向量化模型word2vecModel下的data文件夹中,并广播到所有节点(此处的地址应为本地文件系统file,因为如果有hdfs文件系统可能会查找hdfs文件系统)
1 | sqlContext = SQLContext(sc) |
5、模型训练
5.1情感分析相关的函数定义好后,我们便可从json文件中读入数据,创建RDD对象,利用spark mllib的分类器进行情感分析
5.1.1读入tweetstest.json作为分类器训练数据集
5.1.2解析json数据并赋值给rawTrn_data
5.1.3获取rawTrn_data中的results字段,在获取results字段中的text字段,赋值给Segmentation_text
5.1.4调用doc2vec方法将Segmentation_text文本转换成词向量
5.15利用数据的情感极性和词向量生成向量标签LabeledPoint,追加到trn_data中
5.1.6调用sparkContext对象sc将trn_data序列化成RDD数据
1 | with open('tweetstest.json', 'r') as f: |
5.2读入hillarytest.json作为分类器测试数据集(此处的预测测集为hillarytest.json,也就是预测人们对希拉里的情感极性分布预测,如果想预测唐纳德则将数据文件换成donaldtest.json即可)
5.2.1解析json数据并赋值给rawTst_data
5.2.2获取rawTst_data中的results字段,在获取results字段中的text字段,赋值给Segmentation_text
5.2.3调用doc2vec方法将Segmentation_text文本转换成词向量
5.2.4利用数据的情感极性和词向量生成向量标签LabeledPoint,追加到tst_data中
5.2.5调用sparkContext对象sc将tst_data序列化成RDD数据
5.2.6调用随机森林中的类RandomForest中的训练函数trainClassifier,传入模型训练数据trnData,开始训练模型model
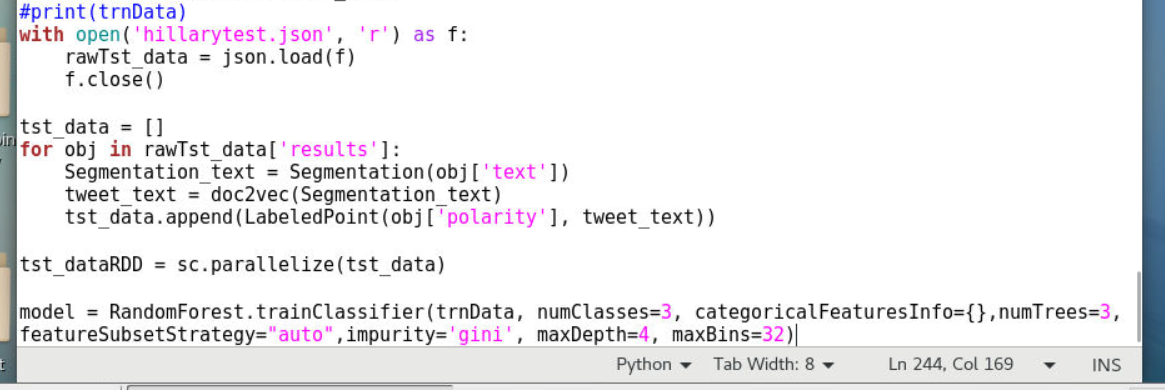
1 | with open('hillarytest.json', 'r') as f: |
6、模型预测
6.1利用训练好的模型model进行模型性能测试,调用模型的predict函数,传入测试集数据tst_dataRDD
1 | predictions = model.predict(tst_dataRDD.map(lambda x: x.features)) |

6.2计算分类错误率,并打印输出训练好的随机森林的分类决策模型
1 | testErr=labelsAndPredictions.filter(lambda(v,p):v!=p).count()/float(tst_dataRDD.count()) |

6.3调用数据可视化函数res_visulization,对训练好的模型进行展示,输出完毕,调用sparkContext对象的stop方法关闭连接
1 | # 结果可视化 |

7、程序运行
7.1编辑代码完成,使用:wq保存退出vim编辑器
7.2利用spark-submit提交程序运行,运行模式为local
1 | (zkbc)[zkpk@master sparkmllib]$ spark-submit --master=local sparktest.py |
7.3等待程序运行,查看界面弹出结果
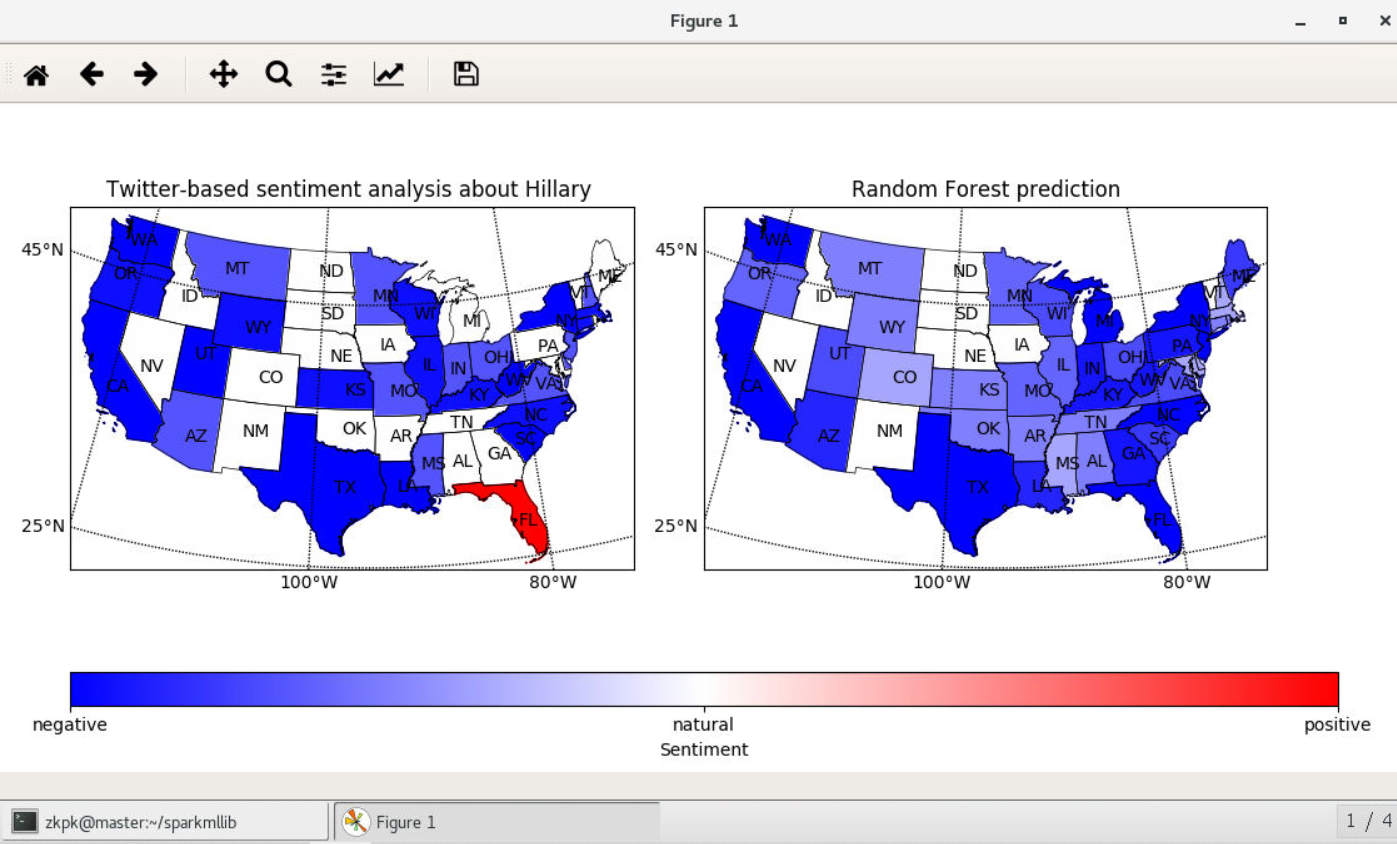
7.4通过可视化结果,我们可以直观的感受到美国曾经的候选总统希拉里在美国各个州的受欢迎程度。我们也可以看到随机森林预测的结果大致准确,但是误差还是不小的,这与模型参数和数据量都有很大的关系,通过设置模型参数和增大数据量都能提升模型准确性,这里就不在赘述了。感兴趣的同学可以参考本实验针对从网络上获取的微博或者推特数据进行其他领域的情感分析,例如:房价、物价、生活幸福度等等
 微信
微信
